








Data Science and Machine Learning - #30 Florestas Aleatórias I
19/12/2021Na aula de hoje aprenderemos um novo modelo de generalização de Aprendizado de Máquina com Python, o modelo de Florestas Aleatórias.
Florestas Aleatórias
Ensembles são combinações de diferentes modelos chamados de �??modelos fracos�?� ou �??modelos base�?� para a criação de um modelos mais forte. E existem 3 principais tipos de ensemble.
As árvores de decisão (que aprendemos na última aula) são um modelo base de algorítimo. Agora imagine se pudéssemos fazer 10 árvores de decisões de uma só vez e depois avaliasse os resultados? Com certeza, teríamos um resultado muito mais preciso.
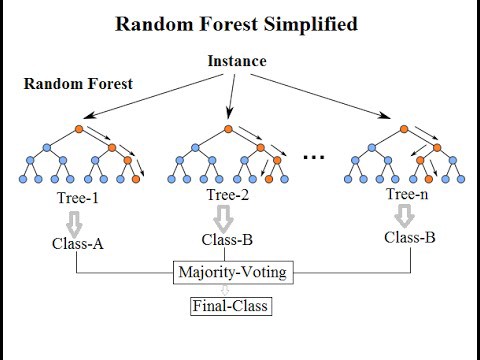
As Florestas Aleatórias nada mais são que um conjunto de árvores de decisão para potencializar o resultado das predições.
O sistema pode ser ilustrado assim:
Importando Módulos
Vamos começar importando os módulos necessários:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
%matplotlib inlineImportando DataFrame
No exemplo de hoje vamos trabalhar com o dataset de Anúncios Sociais presentes no Kaggle.
df = pd.read_csv("social.csv")
df.head()Preparando os Dados
Vamos preparar os dados retirando colunas desnecessárias e transformando strings em dados binários:
del df["User ID"]
idCat, cat = pd.factorize(df["Gender"])
df['GenderCat'] = idCat
#Male=0 / Female=1
del df["Gender"]
df.head()Análise Exploratória
Vamos partir agora para análise exploratória dos dados:
df.info()
df.describe()
sns.pairplot(df,hue="Purchased")
sns.heatmap(df.corr(),annot=True)
sns.jointplot(x="Purchased",y="Age",data=df,kind="reg")
sns.countplot(x="Purchased",data=df)
df["Purchased"].value_counts()
sns.pairplot(df,hue="GenderCat")Por hoje é só! Sucesso nos códigos e na vida!


Posts Relacionados
